 More and more, I’m having to type in extra info when filling out a form online. Most are a string of digits. But one project, reCAPTCHA, uses words. And not just any words — they use words that a computer has trouble recognizing (using Optical Character Recognition, or OCR) in old print editions of the New York Time and from Google Books. They say
More and more, I’m having to type in extra info when filling out a form online. Most are a string of digits. But one project, reCAPTCHA, uses words. And not just any words — they use words that a computer has trouble recognizing (using Optical Character Recognition, or OCR) in old print editions of the New York Time and from Google Books. They say
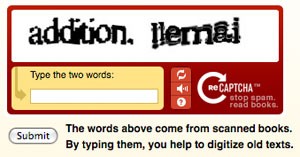
reCAPTCHA improves the process of digitizing books by sending words that cannot be read by computers to the Web in the form of CAPTCHAs for humans to decipher. More specifically, each word that cannot be read correctly by OCR is placed on an image and used as a CAPTCHA. This is possible because most OCR programs alert you when a word cannot be read correctly.
But if a computer can’t read such a CAPTCHA, how does the system know the correct answer to the puzzle? Here’s how: Each new word that cannot be read correctly by OCR is given to a user in conjunction with another word for which the answer is already known. The user is then asked to read both words. If they solve the one for which the answer is known, the system assumes their answer is correct for the new one. The system then gives the new image to a number of other people to determine, with higher confidence, whether the original answer was correct.
Another project, Transcribe Bentham is using the public to do a similar task, although with much less automation. They use “volunteer (who) transcribe previously unstudied and unpublished manuscripts from the Bentham Papers collection.”
I’ve added reCAPTCHA to several websites I maintain. You can find out about transcribing for the Transcribe Bentham here or read more about the project here.